Indentation
Nim is an indentation-based language, like Python. This means that the structure of the code is determined by the indentation level of the lines, and that whitespace is significant. Consider the following example:
proc foo() = # ──────────────────┐0
for i in 0 ..< 10: # ─────────────┐1 │
echo i # ────────┐2 │ │
if i mod 2 == 0: # │ │ │
echo "even" # ── 3 │ │ │
else: # │ │ │
echo "odd" # ── 3 ◄──┘ ◄──┘ ◄──┘
There are four levels of indentation here. The first level is the global scope, which is at indentation 0. Block-defining elements like proc, for, and if statements increase the indentation level. Typically, Nim code uses 2 spaces for indentation, but this is not a strict requirement. And although not recommended, we can use different number of spaces for different levels of indentation, as long as the indentation level within the same block is consistent.
As one might expect, parsing indentation-based languages is more difficult than parsing languages with explicit block delimiters like curly braces. We need to keep track of the indentation level of each line, and we often need to compare the indentation level of a line with the previous lines to determine the structure of the code.
There are two places where we can track indentation: in the lexer or in the parser.
- If we track indentation in the lexer, we need to recognize the indentation level of each line and emit tokens that represent indentation changes, as well as for staying in the same indentation level. These tokens are then consumed by the parser grammar to delimit blocks.
- If we track indentation in the parser, we to be able to access the length of the leading whitespace of the first token of each line. This is not always possible with lexer generators, as they typically don't provide metadata about the tokens they emit. Also, using a parser generator like Grammar-Kit makes it even more challenging to define rules based on the leading whitespace of a token.
While there is a way in Grammar-Kit to write custom utility functions that can be used as grammar rules (which we can use to access the underlying text and calculate the indentation levels), it is not a straightforward process. So, I'm going to take the route of tracking indentation in the lexer. This comes with a different problem though: leading whitespace becomes part of the token stream, and is not ignored by the parser anymore. The grammar rules have to account for cases where indentation tokens are present, when we wish to treat them as whitespace (e.g. at the end of the file).
Indentation Tokens
We will need three kinds of indentation tokens: IND (for increasing indentation), DED (for decreasing indentation), and EQD (for staying at the same indentation). The reason for the EQD token is that we will use it as a separator between successive statements, much the same way as a semicolon in C-like languages.
Let's use these tokens with the example above and see what we need to emit at indentation token(s) we need to emit at each line:
proc foo() =
for i in 0 ..< 10: # IND
echo i # IND
if i mod 2 == 0: # EQD
echo "even" # IND
else: # DED, EQD
echo "odd" # IND
# back to top level # DED, DED, DED
Most of the lines should be easy to understand. But let's look closer at lines 6 and 8 in particular, where we emit multiple tokens. On line 6, the first part of the if/else block ends, and we go back to the same level of the if statement. So we emit both a DED token (to close the if block) and a EQD token (to separate the if block from the else block). On line 8, we close the else block and go back to the top level, which requires emitting three DED tokens to close the else block, the for block, and the proc block.
Lexer State Machine
We'll need to introduce a new BEGIN_LINE state in our lexer, and switch to it once we encounter a new line. We'll also need a stack to keep track of the indentation levels we are in. The stack is initialized with indentation level 0. The following diagram shows the state machine we need to implement.
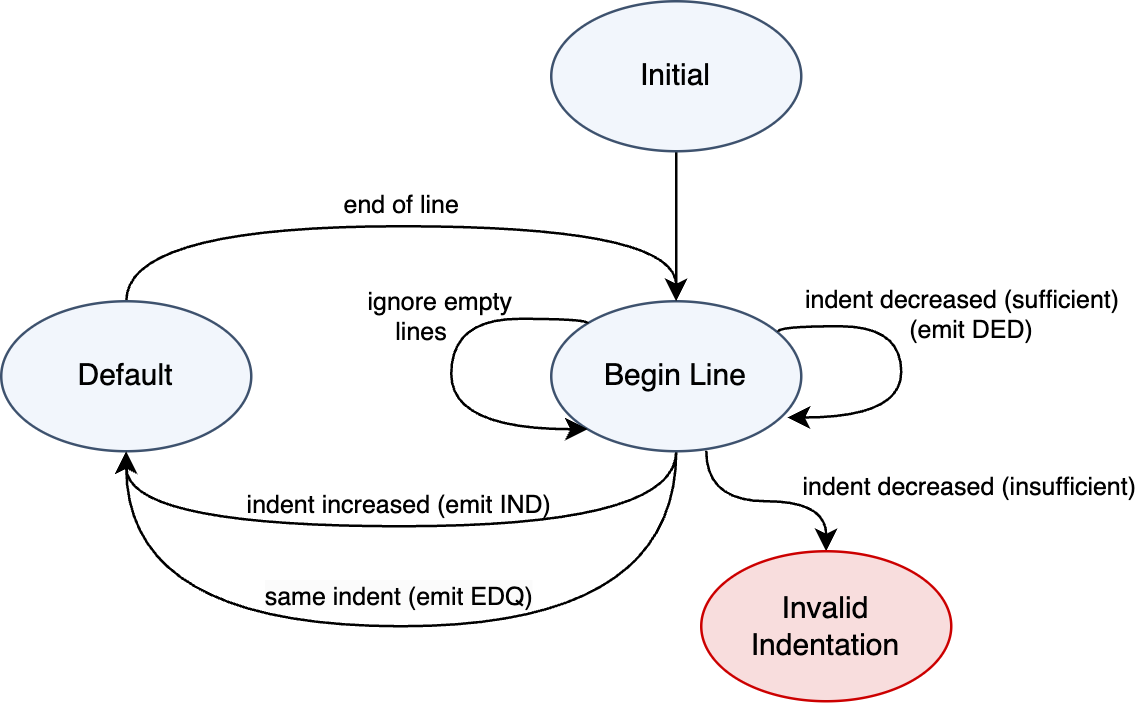
Here's how it works:
- We start in the
YYINITIALstate (the default lexer state). - Since we always start at the beginning of a line, we switch to the
BEGIN_LINEstate. - In the
BEGIN_LINEstate, we treat any empty lines as whitespace. - In the
BEGIN_LINEstate, we use a regex to match the leading whitespace of the line and get its length. This is the indentation level of the line (which could be zero). - We have three cases:
- If the indentation level is greater than the top of the stack, we emit an
INDtoken, push the new indentation level to the stack, and switch to theDEFAULTstate. - If the indentation level is equal to the top of the stack, we emit an
EQDtoken, and switch back to theDEFAULTstate (we don't modify the stack). - The third case handles decrease in indentation, and is more involved than the other two. That's because the decrease in indentation could be insufficient relative to the parent block. So, the rule is:
- If there's more than one level of indentation on the stack, and the current indentation level is less than or equal to the second-to-top level of the stack, we emit a
DEDtoken, pop the stack, but we do not switch back to theDEFAULTstate just yet. Instead, we stay in theBEGIN_LINEstate, push back the whitespace text to the lexer, and let the lexer reprocess the line. This allows us to emit the correct number ofDEDtokens until we reach the correct indentation level.
- If there's more than one level of indentation on the stack, and the current indentation level is less than or equal to the second-to-top level of the stack, we emit a
- If none of the above cases are met, then we have a case where the decrease in indentation is insufficient, and we emit an
INVALID_INDtoken.
- If the indentation level is greater than the top of the stack, we emit an
The logic is a bit intricate, especially for the decrease in indentation case, but it's the price we're willing to pay to keep the parser simple. Let's go ahead and add a processIndentation method to our lexer so that we can call it while in the BEGIN_LINE state.
// src/main/kotlin/khaledh/nimjet/lexer/Nim.flex
...
// lexer class code
%{
private Stack<Integer> indentStack = new Stack<>();
%}
%init{
// initial indentation level is 0
indentStack.push(0);
%init}
%{
private IElementType processIndent() {
int currIndent = yylength();
if (currIndent > indentStack.peek()) {
// new indent level
indentStack.push(currIndent);
yybegin(DEFAULT);
return NimToken.IND;
}
if (currIndent == indentStack.peek()) {
// same indent level
yybegin(DEFAULT);
return NimToken.EQD;
}
if (indentStack.size() > 1 && currIndent <= indentStack.get(indentStack.size() - 2)) {
// We can only dedent one level at a time, so don't switch back to DEFAULT just yet,
// and keep returning DED tokens as long as there's more dedent levels.
indentStack.pop();
yypushback(yylength());
return NimToken.DED;
}
// invalid indentation
return NimToken.INVALID_IND;
}
%}
// lexer states
%state DEFAULT
%state BEGIN_LINE
// macros
EOL = \r\n|\r|\n
%%
<YYINITIAL> [^] { yypushback(1); yybegin(BEGIN_LINE); }
<DEFAULT> {
...
{EOL} { yybegin(BEGIN_LINE); return TokenType.WHITE_SPACE; }
...
}
<BEGIN_LINE> {
[ \t]*{EOL} { return TokenType.WHITE_SPACE; /* skip empty lines */ }
[ \t]* { return processIndent(); }
}
When I tested this on a code sample, the IDE threw an error saying "Lexer is not progressing after calling advance()". At first, I was puzzled by this, so I fired up the debugger and traced the code. It turns out that the IDE tries to validate that the lexer is making progress by ensuring that it doesn't produce the same token multiple times in a row at the same location while in the same state. Unfortunately, that's exactly what we're trying to do when we need to emit multiple DED tokens in a row when the indentation decreases more than one level.
To work around this issue, I created two identical copies of the BEGIN_LINE state: BEGIN_LINE and BEGIN_LINE_2, and updated the DED case to toggle between the two states. It's a hack, but it works.
// src/main/kotlin/khaledh/nimjet/lexer/Nim.flex
...
// lexer class code
%{
...
private IElementType processIndent() {
...
if (indentStack.size() > 1 && currIndent <= indentStack.get(indentStack.size() - 2)) {
// We can only dedent one level at a time, so don't switch back to DEFAULT just yet,
// and keep returning DED tokens as long as there's more dedent levels.
//
// Also, IntelliJ's lexer validation doesn't like returning the same token multiple
// times in a row at the same location while in the same state (throws an exception
// about "Lexer is not progressing"), so as a workaround we toggle between two
// identical states to avoid this issue.
int nextState = yystate() == BEGIN_LINE ? BEGIN_LINE_2 : BEGIN_LINE;
yybegin(nextState);
indentStack.pop();
yypushback(yylength());
return NimToken.DED;
}
}
%}
// lexer states
%state BEGIN_LINE BEGIN_LINE_2
...
%%
// We use two identical states to avoid a lexer validation issue; see processIndent.
<BEGIN_LINE, BEGIN_LINE_2>
[ \t]*{EOL} { return TokenType.WHITE_SPACE; }
[ \t]* { return processIndent(); }
}
This keeps the lexer validation happy, and we can now emit multiple DED tokens in a row from the same location.
Parsing Top-Level Code
Now that we have the indentation tokens in the token stream, we need to modify our parser to use them to delimit blocks. The first obvious change is to delimit the top-level statement list with EQD tokens, since all top-level statements should be at indentation level 0. Let's modify the StmtList rule to account for this.
// src/main/kotlin/khaledh/nimjet/parser/Nim.bnf
{
...
}
Module ::= !<<eof>> StmtList
StmtList ::= Stmt (EQD Stmt)*
Stmt ::= LetSection
| Command
LetSection ::= LET IdentDecl EQ STRING_LIT
Command ::= IdentRef IdentRef
IdentDecl ::= IDENT
IdentRef ::= IDENT
Let's generate the parser (Cmd+Shit+G) and try it out.
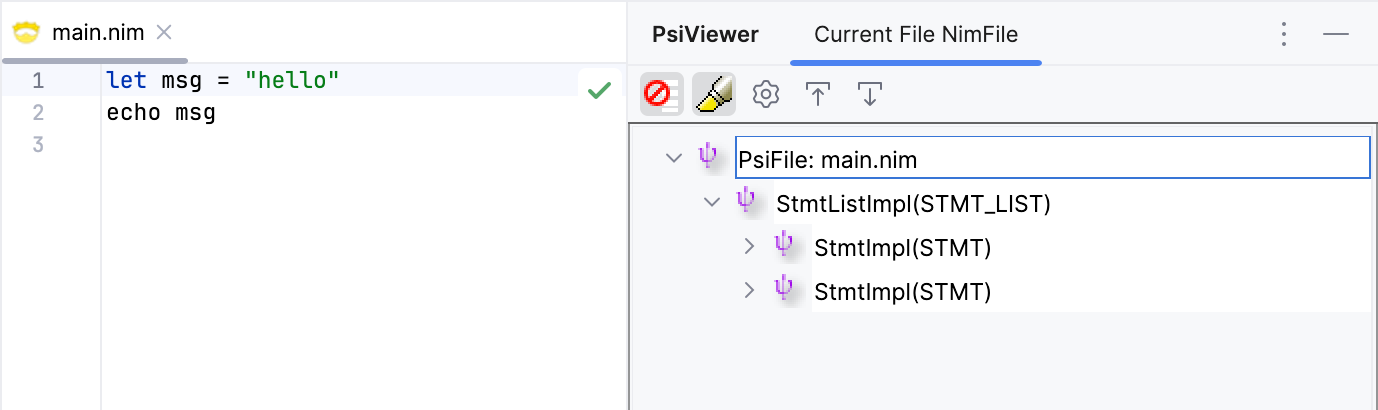
Although there are no visible changes in the PSI tree, the code is parsed correctly as expected. Unfortunately we don't see the EQD token element in the tree as I was expecting. But when I debug the lexer I see it emitting the token. My assumption is that the PSI tree builder doesn't allow multiple elements at the same location, as in this case where the EQD token occupies the same start location as the second Stmt element, and uses the last element (in sibling order) as the element for that location. It's a bit annoying not to be able to verify the existence of token, but it doesn't impact the correctness of the parsed tree. In fact, it could be considered a good thing, since, conceptually, indentation elements should be considered whitespace, which normally doesn't show up in the tree.
This works, but there's a few issues we need to address. Let's introduce an empty line at the beginning of the file.
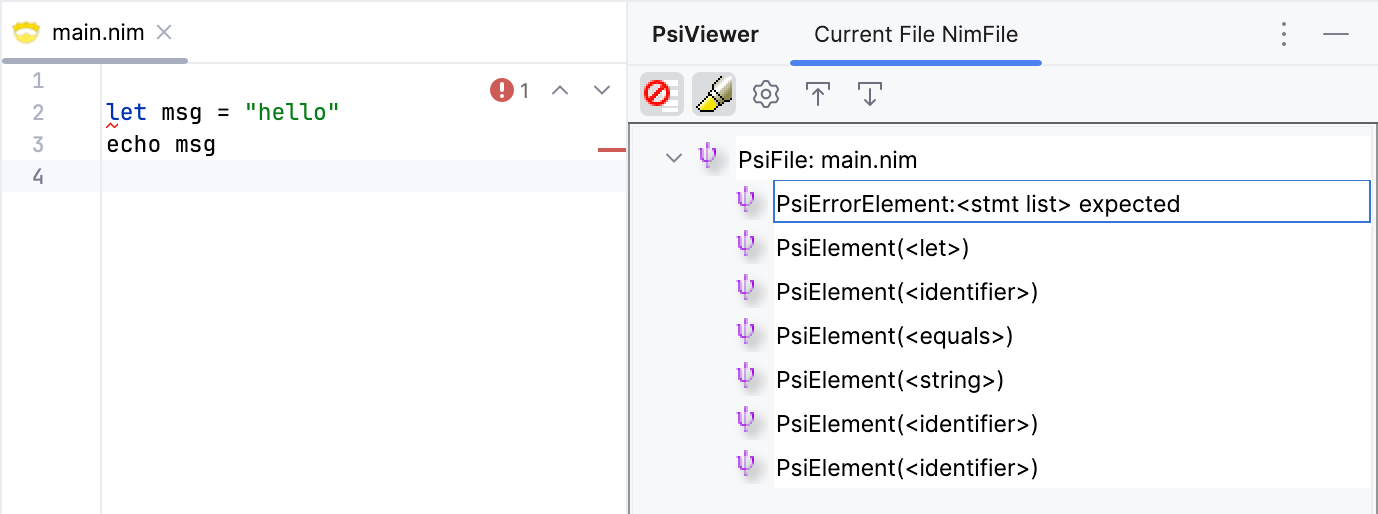
We get an error saying that <stmt list> was expected at the beginning of the second line. The reason is that the lexer emitted an EQD token for the empty line, which is not expected by the parser at that location. We can easily fix this by skipping whitespace at the beginning of the file. Instead of introducing more rules to handle this, we can just use a flag firstNonEmptyLine (defaults to true), to decide whether we're processing the first line or not, and act accordingly.
// src/main/kotlin/khaledh/nimjet/lexer/Nim.flex
...
%{
private Stack<Integer> indentStack = new Stack<>();
private Boolean firstNonEmptyLine = true;
%}
...
%{
private IElementType processIndent() {
int currIndent = yylength();
// we don't want to emit EQD for the first non-empty line
if (firstNonEmptyLine && currIndent == 0) {
firstNonEmptyLine = false;
yybegin(DEFAULT);
return TokenType.WHITE_SPACE;
}
...
%}
This should fix the issue with the first non-empty line. Let's test it out.
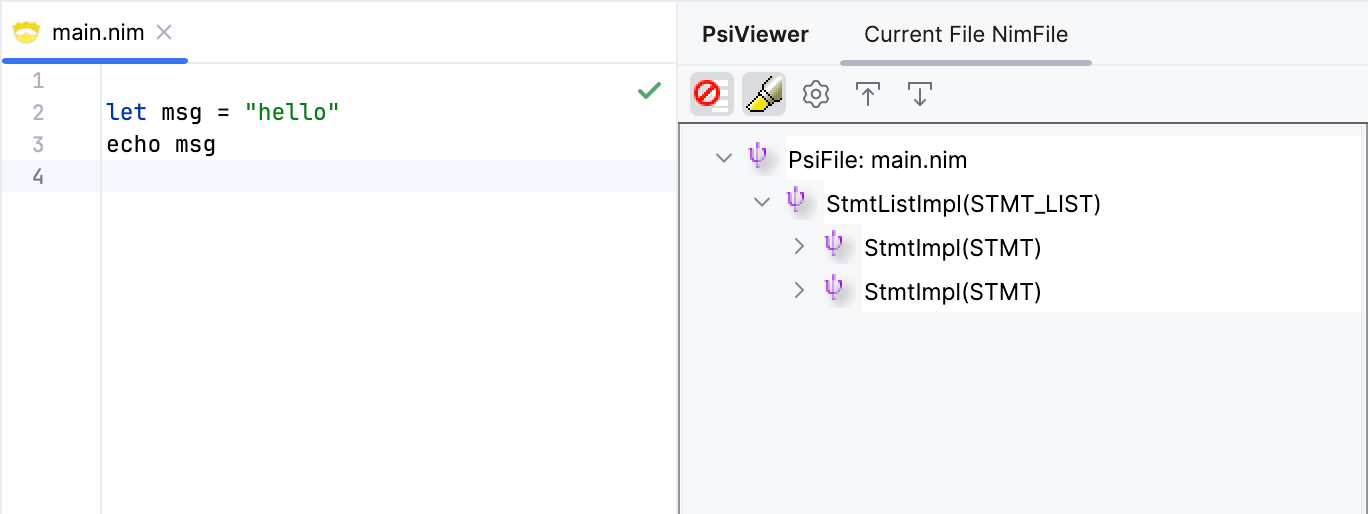
Great! Let's also test the case where the first non-empty line has leading whitespace.
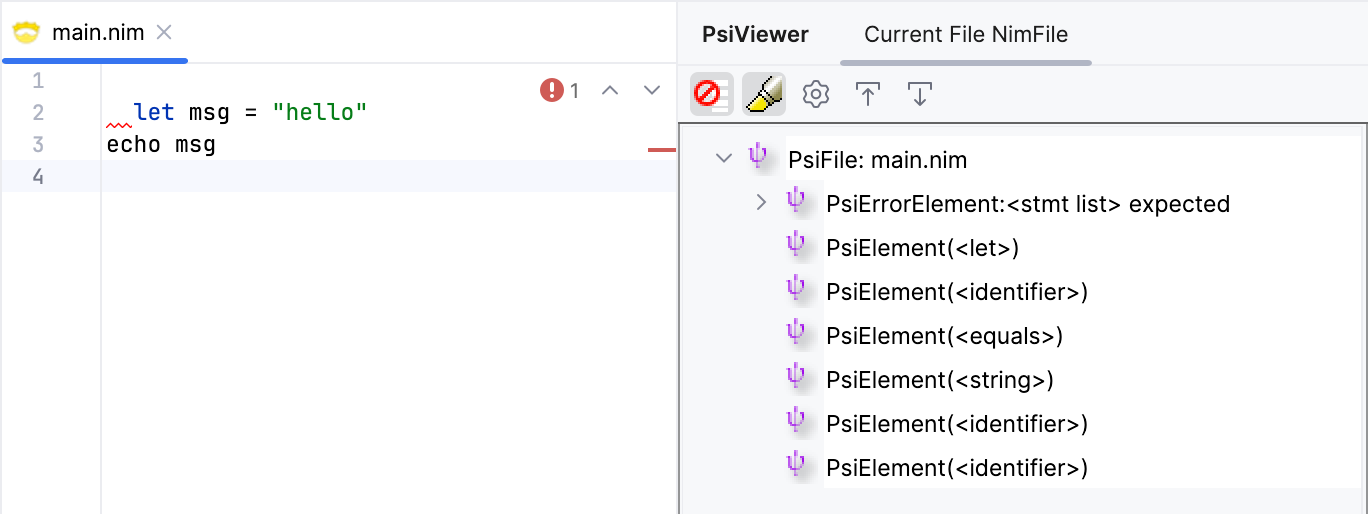
We get an error as expected! Our lexer and parser can now recognize and handle top-level indentation correctly.
Parsing Blocks
Now that we have the top-level statement list working, let's move on to parsing blocks with actual indentation. The simplest construct in Nim that uses indentation is the block statement, which contains an indented StmtList inside it, including nested block statements.
Let's start by adding a BLOCK token to our lexer (and define the corresponding token in NimToken).
// src/main/kotlin/khaledh/nimjet/lexer/Nim.flex
...
<DEFAULT> {
...
"let" { return NimToken.LET; }
"block" { return NimToken.BLOCK; }
...
}
Next, let's add a new rule for BlockStmt in our parser.
// src/main/kotlin/khaledh/nimjet/parser/Nim.bnf
...
BlockStmt ::= BLOCK COLON IND StmtList DED
The rule is simple: a block statement starts with the block keyword, followed by a colon, and a StmtList enclosed between IND and DED tokens. Let's generate the parser and test it out.
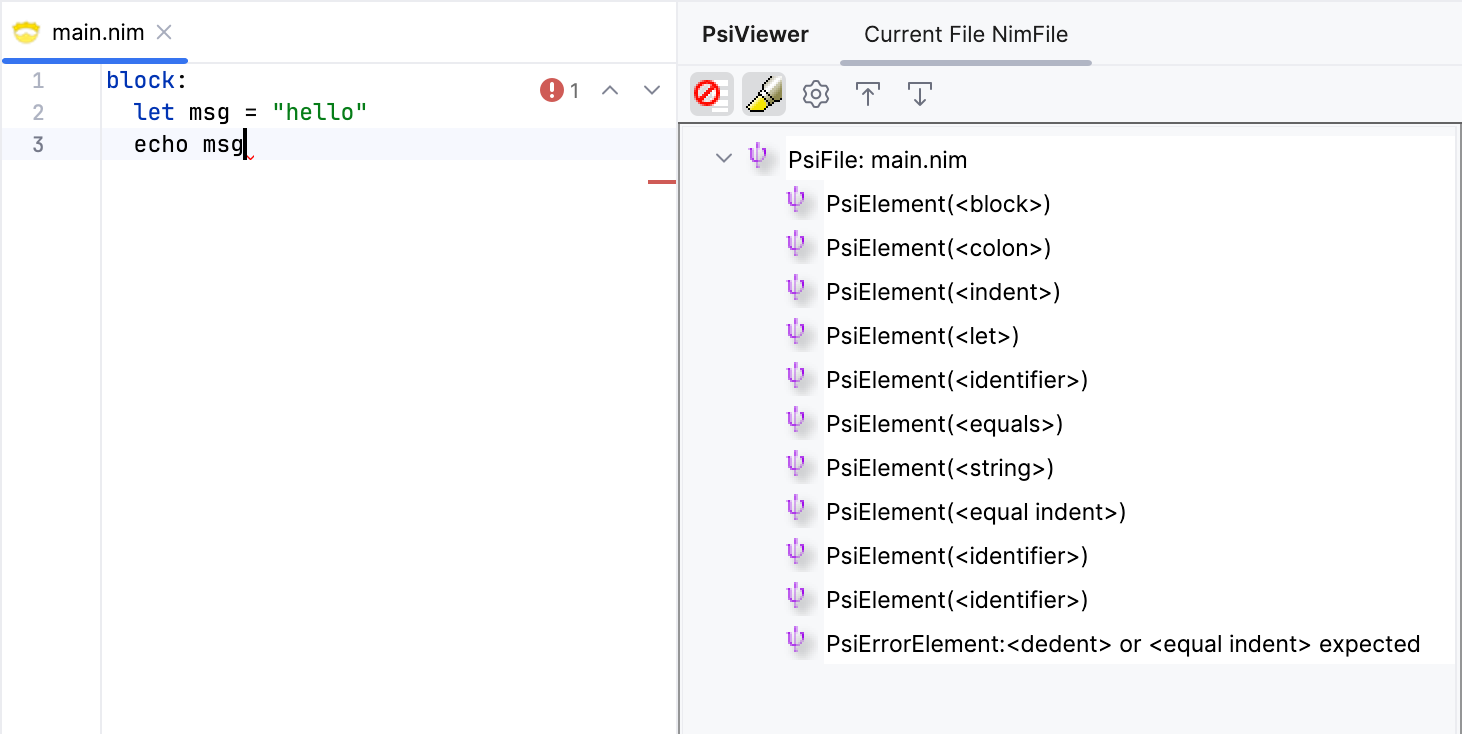
We get an error saying that the parser was expecting either a DED or EQD at the end. That's because the file ends right after the last statement, and so there are no indentation tokens to close the block. This is a problem we cannot solve at the lexer level, unfortunately. What we can do, is to allow blocks to end with either a DED token or the <<eof>> special marker. Since we're going to need this for other rules, let's introduce a private rule DED_OR_EOF that matches either a DED token or the end of file, and use it in places where we expect a DED token. A private rule means it doesn't get a dedicated node in the PSI tree.
// src/main/kotlin/khaledh/nimjet/parser/Nim.bnf
...
BlockStmt ::= BLOCK COLON IND StmtList ded_or_eof
private ded_or_eof ::= DED | <<eof>>
This solves the problem of blocks ending at the end of the file. Let's test another scenario where we create a new line that has the same indentation level inside the block, but that doesn't contain a statement, i.e. the end of file comes right after the leading whitespace.
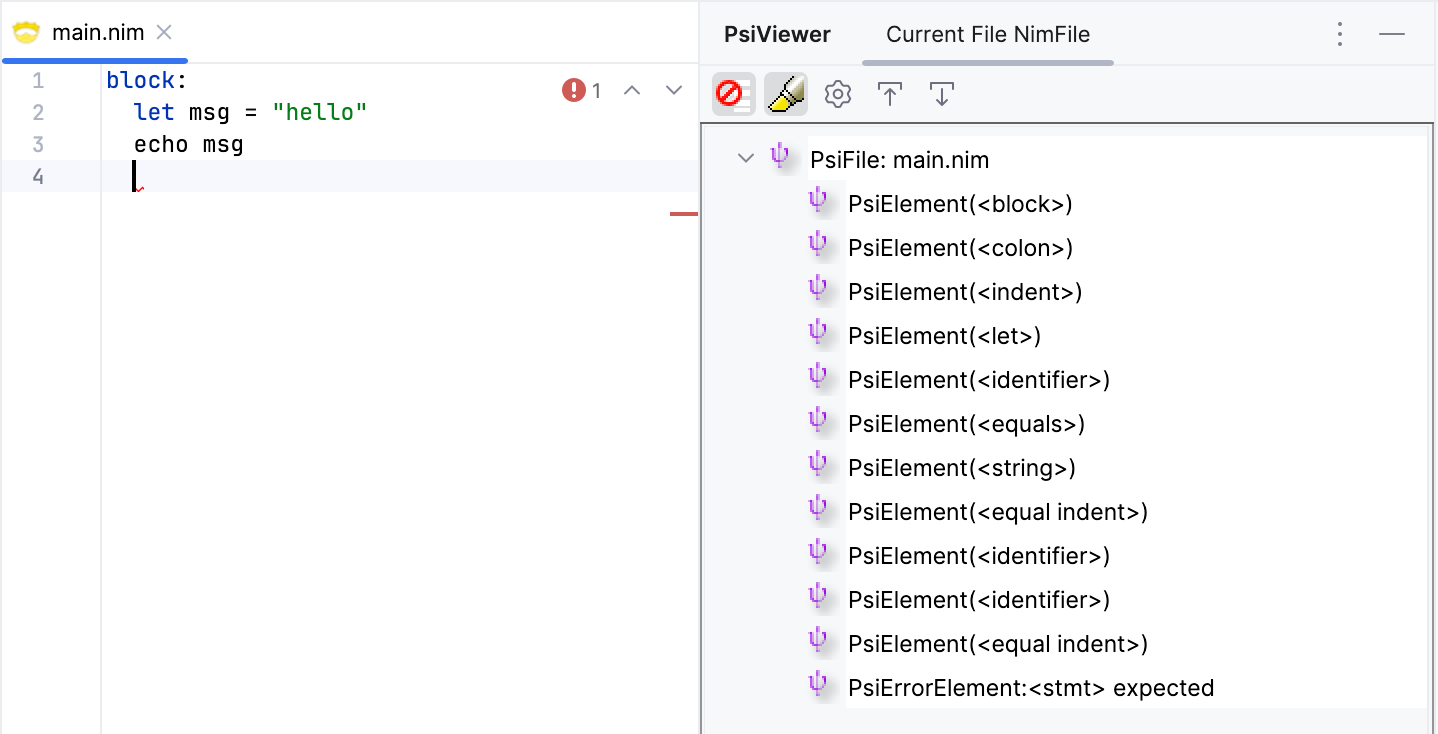
We get an error that says <stmt> expected. This is an issue similar to the one above. The lexer had emitted an EQD token at that location, and so the parser expects a statement to come after it. While the behaviour here is correct, and can be fixed by expecting the user to remove the leading whitespace, it's not a good experience. Users expect empty lines anywhere in the file to be ignored.
We can do something similar to allowing blocks to end with <<eof>> by modifying the StmtList rule to make the Stmt instance that comes after EQD optional, but this situation might come up in other places in the future as well. So it's better to solve it at the lexer level by treating a line with only whitespace at the end of the file as whitespace.
Unfortunately, there's no official way to match the end of file as part of a regex in JFlex. There's an <<EOF>> rule that matches the end of file, but it can only be used alone, and not as part of a regex. If we try to use it alone, it would be too late, since the leading whitespace according to our indentation rules, and we may have already emitted an indentation token. So, I'm going to rely on a private variable in the generated lexer class called zzEndRead to get the end of file position (I know, I shouldn't use unofficial features, but I have no other way), and use it to determine if the end of the current line is at the end of the file. If it is, we return a whitespace token.
// src/main/kotlin/khaledh/nimjet/lexer/Nim.flex
%{
...
private IElementType processIndent() {
int currIndent = yylength();
// handle a line with only whitespace at the end of the file
if (getTokenEnd() == zzEndRead) {
return TokenType.WHITE_SPACE;
}
...
}
...
This should solve the issue, treating the last line as whitespace if it's empty. The parser should be happy, since there's no extra indentation tokens at the end of the file.
With this modification in place, we can actually revisit the situation that required us to add the ded_or_eof rule to handle the end of file in blocks. We can now add a lexer rule to match the EOF in any state, and pop all the remaining indentation levels from the stack, emitting an DED for each of them. The reason we couldn't do this before is that, in the case where the last line contains only whitespace, we would have emitted a EQD first, followed by the DED tokens from the stack, which would have been incorrect. But now that we ignore the last line if it's empty, we can safely emit those DED tokens once we encounter the end of file.
Let's add a new method processEof() to our lexer to handle this, and call it when we encounter the end of file from any state.
%{
...
private IElementType processEof() {
// return DED tokens (one at a time) for all remaining indent levels
if (indentStack.size() > 1) {
indentStack.pop();
return NimToken.DED;
}
return null;
}
%}
...
<<EOF>> { return processEof(); }
processEof() will be called multiple times (lexer stays at EOF) until the stack is empty, at which point we return null to indicate that there are no more tokens.
If we test this we run into the same issue as before, where the lexer doesn't progress because it's returning the same token (DED) multiple times in a row at the same location. So, we need to use the same trick as before, and toggle between two identical states to avoid this issue.
%{
...
private IElementType processEof() {
// return DED tokens (one at a time) for all remaining indent levels
if (indentStack.size() > 1) {
indentStack.pop();
int nextState = yystate() == AT_EOF ? AT_EOF_2 : AT_EOF;
yybegin(nextState);
return NimToken.DED;
}
return null;
}
%}
...
%states AT_EOF AT_EOF_2
%%
...
<<EOF>> { yybegin(AT_EOF); }
<AT_EOF, AT_EOF_2> <<EOF>> { return processEof(); }
This should handle the end of file issue correctly, emitting the correct number of DED tokens to close any open blocks.
Now, let's remove the ded_or_eof rule from the BlockStmt rule, and revert it back to its simpler form.
BlockStmt ::= BLOCK COLON IND StmtList ded_or_eof
BlockStmt ::= BLOCK COLON IND StmtList DED
private ded_or_eof ::= DED | <<eof>>
Much better!
I believe this takes care of all the indentation issues. Not bad; for a few dozen lines of lexer code we have a working indentation-based parser. We can now focus on adding more grammar rules that build on top of this.