Scope Resolution
The current implementation of the resolve method in IdentReference is very naive. It only looks for the first IdentDecl element in the file, and returns it if the name matches the reference. This won't work in a real-world scenario where there could be multiple matching declarations in the file at different scopes. For example, consider the following code snippet (we haven't implemented block statements yet, but let's assume we have):
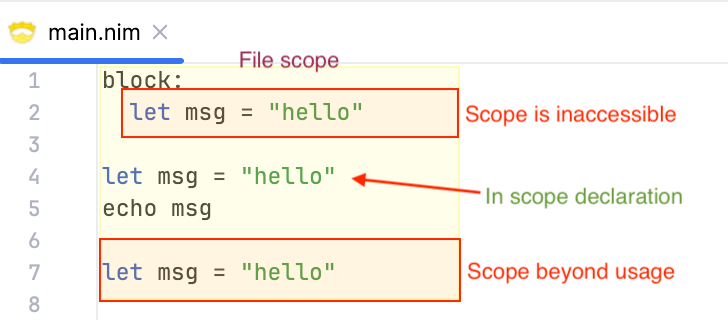
There are three declarations in this file:
- Line 2:
msgdeclaration in ablockscope. This scope is inaccessible to theechostatement. - Line 4:
msgdeclaration in the file scope before the reference. This is the correct declaration that the reference should resolve to. - Line 7:
msgdeclaration in the file scope after the reference. This scope is also inaccessible to theechostatement.
We need to change our implementation of the resolve method to handle those scoping rules.
Tree Walk-Up
The IntelliJ platform provides a mechanism for scope-based resolution. It's a bit complex, but it allows us to define custom scopes and resolve references within those scopes. It works as follows:
- When
resolveis called on a reference, we perform a tree walk-up to find the scope in which the reference is resolved. ThePsiTreeUtil.treeWalkUputility method can be used for this purpose. This method takes an instance ofPsiScopeProcessorinterface that is responsible for deciding whether a particular element is the target of the reference. - The
treeWalkUpmethod iterates over the ancestors of the reference element, and calls aprocessDeclarationsmethod on each of them, passing thePsiScopeProcessorinstance. - For each of the ancestors, their respective
processDeclarationsmethod is called. This method is responsible for finding the declarations in the scope of that ancestor. - For each declaration found, the
executemethod of thePsiScopeProcessoris called. This method is responsible for deciding whether the declaration is the target of the reference. This is typically done by comparing the name of the declaration against the name of the reference. If a match is found, theexecutemethod returnsfalseto stop the iteration, and the declaration is returned as the result of theresolve. If a match is not found, theexecutemethod returnstrueto continue the iteration.
To better understand the tree walk-up mechanism, let's take a look at the implementation of the treeWalkUp method from the PsiTreeUtil class:
public static boolean treeWalkUp(@NotNull PsiScopeProcessor processor,
@NotNull PsiElement entrance,
@Nullable PsiElement maxScope,
@NotNull ResolveState state) {
PsiElement prevParent = entrance;
PsiElement scope = entrance;
while (scope != null) {
if (!scope.processDeclarations(processor, state, prevParent, entrance)) return false;
if (scope == maxScope) break;
prevParent = scope;
scope = prevParent.getContext();
}
return true;
}
In a nutshell, the treeWalkUp method iterates over the ancestors of the entrance element, starting with the entrance element itself, passing the processor instance to the processDeclarations method of each ancestor. The iteration stops in one of two cases:
- if
processDeclarationsreturnsfalse, indicating that the target element has been found, or - if the
maxScopeis reached (in our case, that would be the top-levelNimFileelement).
On every iteration, the treeWalkUp method moves up one level to the next "context" of the current element. The getContext method is defined in the PsiElement interface, and by default returns the parent of the element (it delegates to getParent). However, we're free to override this method in our custom PSI elements to return the parent "scope" of the element, which is not necessarily the parent element.
In the example above, if we were to use the default implementation of getContext, the treeWalkUp method would iterate over the following ancestors, in order: Command -> Stmt -> StmtList -> NimFile. However, when doing scope-based resolution, we can skip over intermediate ancestors that don't define their own scope, and only consider the ones that do. In this particular example, there's only one scope that we need to consider: the NimFile node. When we implement other scope-defining elements like block, proc, for loops, etc., we'll consider them as well.
Let's go ahead and implement the getContext method for the IdentRef element, which should return the closest ancestor that defines a scope.
// src/main/kotlin/khaledh/nimjet/psi/impl/IdentRefMixin.kt
...
abstract class IdentRefMixin(node: ASTNode) : ASTWrapperPsiElement(node), IdentRef {
companion object {
private val SCOPE_ELEMENT_TYPES = arrayOf(NimFile::class.java)
}
override fun getContext(): PsiElement? {
return PsiTreeUtil.getParentOfType(this, *SCOPE_ELEMENT_TYPES)
}
...
}
Fortunately, the PsiTreeUtil class provides a utility method called getParentOfType that we can use to find the closest ancestor of one of the specified types. Since we're going to add more scopes later, we define a SCOPE_ELEMENT_TYPES array that contains the classes of the scope-defining elements. So far, we only have the NimFile class in the array.
Scope Processor
We now know how to find the ancestor scopes of a reference. The next step is to try to find the target declaration within each of those scopes, until either the target is found or we run out of scopes.
Let's use the example above to illustrate how this works.
- We create an implementation of
PsiScopeProcessor, let's call itIdentScopeProcessor. Itsexecutemethod will compare the name of the declaration against the name of the reference, and returnfalseif they match (which stops the iteration), andtrueotherwise. - When
resolveis called onIdentReference, thetreeWalkUpmethod is called, passing an instance ofIdentScopeProcessor. - The
treeWalkUpmethod iterates over the ancestor scopes of theIdentRefnode, starting with the reference element itself. In this particular case, the only
ancestor scope is theNimFile(as returned by thegetContextmethod of theIdentRefnode). - The ancestor's
processDeclarationsmethod is called with theIdentScopeProcessorinstance. In our case, theNimFilenode will have aprocessDeclarationsmethod that will look for declarations under its scope. - For each found
IdentDeclnode, theexecutemethod of theIdentScopeProcessorinstance is called. If the name of the declaration matches the name of the reference, theexecutemethod will returnfalse, which stops the iteration and returns the declaration as the result of theresolvemethod.
With this in mind, let's implement the IdentScopeProcessor class:
// src/main/kotlin/khaledh/nimjet/psi/IdentScopeProcessor.kt
...
class IdentScopeProcessor(private val name: String) : PsiScopeProcessor {
var result: PsiElement? = null
override fun execute(element: PsiElement, state: ResolveState): Boolean {
if (element is IdentDecl && element.name == name) {
result = element
return false
}
return true
}
}
How it works:
- The
nameof the target declaration to be found is passed to the constructor. - The
resultfield holds the target declaration if found. - The
executemethod is called for each declaration in the scope. If the name of the declaration matches the name of the reference, we set theresultfield to the declaration and returnfalseto stop the iteration. Otherwise, we returntrueto continue to the next declaration (if any).
Now let's modify the resolve method in the IdentReference class to use this scope processor.
// src/main/kotlin/khaledh/nimjet/psi/IdentReference.kt
...
class IdentReference(element: IdentRef, textRange: TextRange)
: PsiReferenceBase<IdentRef>(element, textRange) {
override fun resolve(): PsiElement? {
val processor = IdentScopeProcessor(element.text)
PsiTreeUtil.treeWalkUp(
processor, // scope processor
element, // entrance element
element.containingFile, // max scope
ResolveState.initial() // initial state
)
return processor.result
}
}
The new implementation should be straightforward to understand. We create an instance of IdentScopeProcessor with the name of the reference, and pass it to the treeWalkUp method. We also pass the reference element as the entrance element (i.e. the starting point of the tree walk-up), and the containing NimFile as the maximum scope. The ResolveState.initial() method creates a state object that can be used to store additional information during the resolution process (we're not making use of it in our case). Finally, we return the result field of the IdentScopeProcessor, whether it's null (if the target declaration wasn't found) or the found declaration.
Processing Declarations
The last missing piece is to implement the processDeclarations method in the NimFile class. It turns out that processing declarations is the same under any scope, so we'll implement it once in a separate class and reuse it in all scope-defining elements.
Let's add a NimScope singleton object that contains the processDeclarations method.
object NimScope {
val SCOPE_ELEMENT_TYPES = hashSetOf(NimFile::class)
fun processDeclarations(
scopeElement: PsiElement,
processor: PsiScopeProcessor,
state: ResolveState,
lastParent: PsiElement?,
place: PsiElement
): Boolean {
// Get all descendants, stopping at new scopes or subtrees that we have already processed
var decls = scopeElement.descendants(
canGoInside = {
it === scopeElement ||
it !== lastParent &&
it::class !in SCOPE_ELEMENT_TYPES
}
)
// Keep only declaration elements
decls = decls.filterIsInstance<IdentDecl>()
// Keep the ones that are declared before the reference element
decls = decls.filter { it.startOffset < place.startOffset }
// Now process each declaration
return decls.all { processor.execute(it, state) }
}
}
We're leveraging the descendants extension function to get all the descendants of the scope element. This function takes a canGoInside lambda that determines whether the function should descend into the children of the current element (the element being visited). There are three cases where we continue descending:
- If the current element is the scope element itself (since
descendentsincludes starting element), - If the current element is not the last parent of a subtree that we already processed,
- If the current element is not a scope-defining element.
The last condition is important because we don't want to descend into new scopes, which would be inaccessible to the reference (like the block scope in the example).
We then perform two filtering operations on the descendants:
- We keep only the
IdentDeclelements, - We keep only the declarations that come before the reference element.
Finally, we use the all function on those declarations to process each of them. If any of the declarations returns false from the execute method, the all function will return early and stop the iteration. Otherwise, it will return true to indicate that no matching declaration was found.
The last thing we need to do is call this method from the processDeclarations method of the NimFile class.
class NimFile(viewProvider: FileViewProvider) : PsiFileBase(viewProvider, NimLanguage) {
...
override fun processDeclarations(
processor: PsiScopeProcessor,
state: ResolveState,
lastParent: PsiElement?,
place: PsiElement
): Boolean =
NimScope.processDeclarations(this, processor, state, lastParent, place)
}
Before we forget, we also need to update the IdentRefMixin class to use the same SCOPE_ELEMENT_TYPES array from the NimScope object, instead of defining it locally (which could easily diverge). Since the logic for finding the scope element is the same for all scope-defining elements, we can actually put that logic in the NimScope object itself.
...
object NimScope {
val SCOPE_ELEMENT_TYPES = hashSetOf(NimFile::class, BlockStmt::class)
...
fun parentScope(element: PsiElement): PsiElement? {
val scopeElementTypes = SCOPE_ELEMENT_TYPES.map { it.java }.toTypedArray()
return PsiTreeUtil.getParentOfType(element, *scopeElementTypes)
}
}
Now we can use the parentScope method in the IdentRefMixin class to find the scope element.
abstract class IdentRefMixin(node: ASTNode) : ASTWrapperPsiElement(node), IdentRef {
override fun getContext(): PsiElement? = NimScope.parentScope(this)
...
}
This should take care of the scope resolution for the IdentReference class.
Testing Scope Resolution
Let's test it out. I modified the BNF grammar temporarily to include the block statement so that I can test the scope resolution (I used a semicolon to terminate the block, since we don't have indentation-based parsing yet).
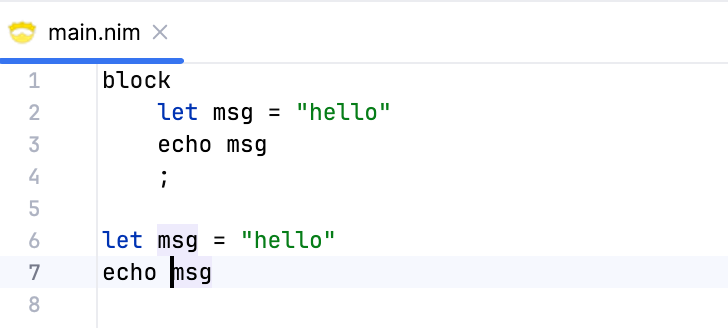
Notice that the highlighted msg reference in the global scope now resolves to the correct declaration right above it, and not the one in the block scope, even though the block scope appears first in the file. Now, let's look at the block scope.
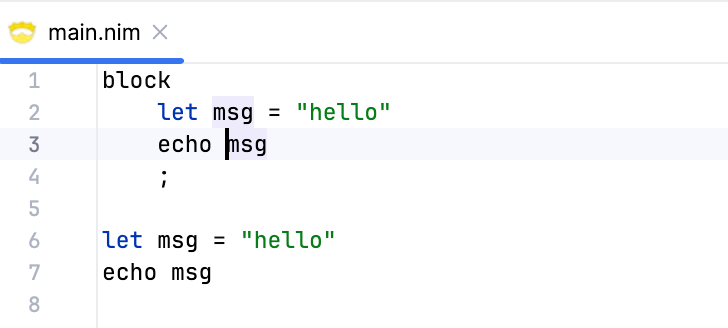
Great! The highlighted msg reference in the block scope resolves to the correct declaration inside the block, and the other reference in the global scope is not highlighted. Also, if we move the declaration after the reference, the reference doesn't resolve to it, which is the correct behavior.
We've reached an important milestone. Resolving references according to scoping rules is a semantic feature that is crucial for any language plugin. The groundwork we've laid here will enable additional features such as find usages, rename refactoring, code completion, and others.